In the last few pieces, I’ve discussed streaming ML evaluation, thought about what to monitor (across state and component axes), and explored failure modes in existing software monitoring tools (e.g. Prometheus). In this final piece, I propose a broader research agenda for problems in ML monitoring,1 motivated by “real-world” post-deployment ML issues.
Preliminaries
We’ll walk through this agenda using an example:
- Task: For a taxi ride, we want to predict the probability that a taxi rider will give a driver a tip greater than 10% of the fare. This is a binary classification problem. Predictions are float-valued between 0 and 1.
- Dataset: We use data between January 1, 2020 and May 31, 2020 collected from the NYC Taxi Coalition. This is an example of “temporally evolving tabular data” (phrase stolen from Arun Kumar).
- SLI: We measure accuracy, or the fraction of correctly-predicted examples when rounded to the nearest integer. In ML communities, the SLI is commonly referred to as the evaluation metric.
- Pipeline architecture: Our example only includes one model.2 There are two pipelines – representing training and inference – that share some components, like cleaning and feature generation. Refer to the third piece in this series for a diagram.
Umbrella of Challenges
My research agenda is focused primarily on data management, rather than algorithms.
Metric Computation
I separate metric computation into coarse-grained and fine-grained categories.3 Coarse-grained metrics are SLIs (e.g., accuracy, precision, recall) that map most closely to business value and require some feedback, or labels. We use coarse-grained metrics to detect ML performance issues. Fine-grained metrics are metrics that might indicate or explain changes in coarse-grained metrics and don’t necessarily require labels (e.g. KL divergence between two consecutive sliding windows of a feature). We use fine-grained metrics to diagnose ML performance issues. Related, I think many organizations fall into this trap of monitoring fine-grained metrics first, as if some change on the median value of an obscure feature will give any actionable insight on whether to retrain a model, when coarse-grained metrics should be treated as first-class citizens.
Coarse-grained Monitoring: Detecting ML Performance Issues
Surprisingly, organizations find it challenging to know the real-time value of their SLIs. Some reasons are:
Separation between prediction and feedback components. If one pipeline makes predictions while another ingests feedback, we’d need to perform joins on a high-cardinality attribute. This may not be a research problem per se, but an annoying engineering problem to think about, especially in the streaming setting.
Changing subpopulations of interest. Many organizations monitor SLIs for different subpopulations (e.g. customers) Over time, new subpopulations or demographics might gradually enter the data stream. It’s hard for organizations to know what subpopulations to monitor – taking into account coverage (i.e. support), time-variation, or high training losses.
Label lag. As a consequence of separation between prediction and feedback components, after we make a prediction, its corresponding feedback (i.e. label) arrives in the system after some time (or not at all). Delays may not be uniform across different predictions or subgroups. Lag is exacerbated in situations where humans are required to manually label data. Furthermore, we assume that label lag is a nonstationary time series (i.e. unanticipated issues may cause lag, and there might not be a pattern to it).
Scalable Monitoring Infrastructure
Tackling the first two problems, especially at scale, calls for better monitoring infrastructure that prioritizes incrementally maintained joins, flexible definitions of SLIs (i.e. user-defined functions), intelligent suggestions for what to monitor, and the ability to add new SLI definitions post-deployment and compute them over historical windows of data. My last piece demonstrated how Prometheus doesn’t meet any of these needs. To this end, I’m thinking about an ML monitoring system with the following layers:
Storage. We’d need a time-series database for persistent storage (computed metric values, histograms or summaries, raw outputs, and feedback) and in-memory streams for fast joins and metric computation.
Execution. Users should be able to specify metric functions as Python UDFs, which we could run incrementally on windows of data with a differential dataflow-based system (Murray et al.). Consider a hypothetical user workflow:
def compute_accuracy(curr_true, curr_pred):
return float(sum(curr_true == curr_pred) / len(curr_true)))
t = Task(name="high_tip_prediction", description="Predicting high tip for a taxi driver")
t.registerMetric(name="accuracy", window=timedelta(hours=2), fn=compute_accuracy)
...
# Under the hood, we automatically compute metrics based on
# params defined above. User calls the following:
t.logOutputs(...)
t.logFeedback(...)
In the workflow above, users define their own metric functions and instrument their code with logging functions. We would need to join outputs and feedbacks – incrementally, to save time – and compute metrics over arbitrary window sizes. A preliminary prototype4 to compute streaming ML SLIs, defined as Python UDFs, across different components, shows promising metric computation time and minimal logging overhead:
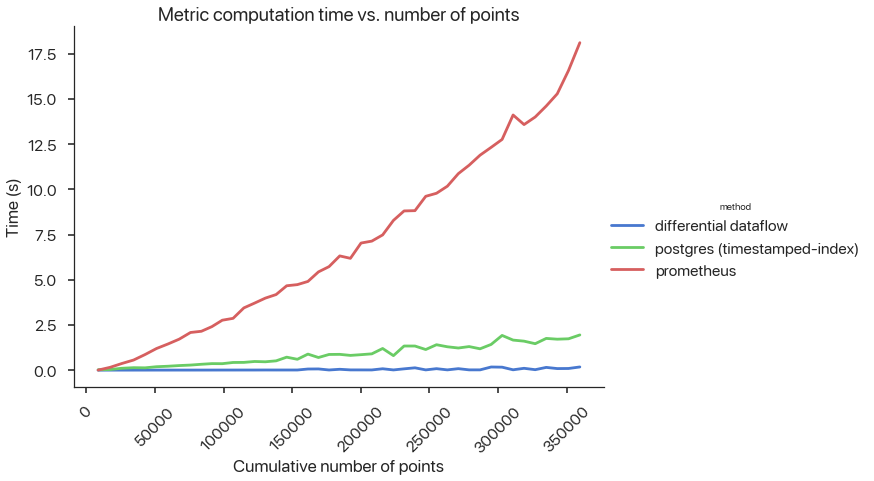
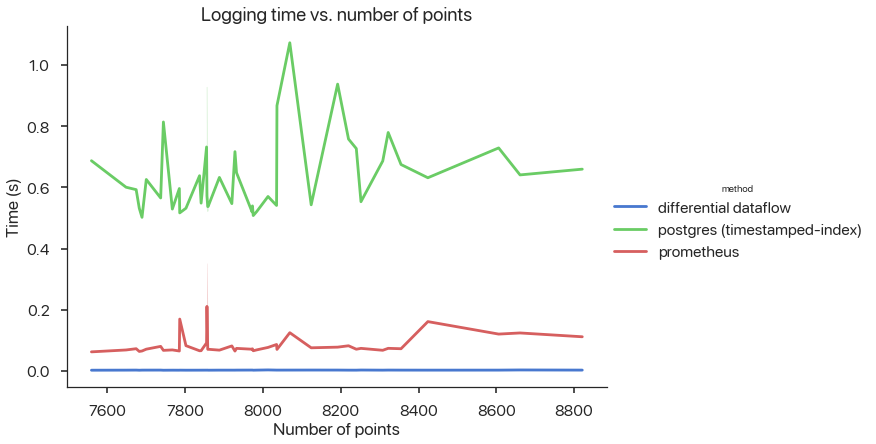 Figure 1: ML query and logging latency.
Figure 1: ML query and logging latency.
Querying. Supporting fast and flexible queries is of utmost importance. Precomputing and storing summaries – including joins and metric values – before users query yields the lowest latency queries; however, users may want to vary window sizes and other parameters at query time. What is the best tradeoff between precomputing before query time and computing everything on the fly? Furthermore, as users add new UDFs and new subgroups arise over time, how do we efficiently backfill metric values for all windows since deployment?
Estimating Real-Time SLIs with Label Lag
Not only do we need to consider monitoring infrastructure, but we also need to be able to compute SLIs correctly. Lag introduces interesting algorithmic challenges to computing SLIs. If users don’t receive labels (feedback) for all predictions in a timely manner, how do we estimate real-time SLIs as correctly as possible?
Full-Feedback
To compute an SLI over a window in this case, we simply need to perform a streaming join. Challenges occur at scale, or when our window size is too large to fit predictions and feedback in-memory. One natural solution might be to perform approximate streaming joins, but it is well-known that uniformly subsampling streams before a join can yield quadratically fewer tuples in the result (Chaudhuri et al.). Existing approximate query processing (AQP) techniques for streaming joins trade off accuracy between the number of tuples or the representativeness of the resulting join. In our case, we care about the latter because we want to minimize the error of our SLI approximation (i.e. approximated accuracy should be close to exact accuracy). So we might not want to leverage state-of-the-art universe sampling techniques (Kandula et al.) that retain large numbers of join result tuples because they don’t necessarily provide accurate estimates (Huang et al.).
To prioritize representativeness in our joined sample, we can draw inspiration from stratified sampling techniques in progressive approximate joins (Tok et al.). Intuitively, to minimize the error of our SLI approximation, we should construct strata, or subgroups, that share similar prediction errors (i.e. losses deemed by the ML model objective). Unfortunately, in our high-data setting, we can’t compute errors for each prediction (because we can’t join each prediction on its corresponding label)! Maybe we can identify “exemplars” (i.e. “important” data points) in high-level feature groupings and join exemplars on group labels. For example, in our high tip prediction problem, we can group our predictions and labels by neighborhood (e.g. FiDi, Tribeca, Midtown), pick exemplars in these groups, aggregate predictions and labels for these exemplars, and join them to compute metrics. Research challenges lie in devising efficient, high-accuracy methods – possibly a hybrid of ML and data processing techniques – to compute groups and exemplars.5
No-Feedback
This scenario typically occurs immediately after deployment. In our NYC taxicab example, suppose we have two sources of raw data: taxi sensor telemetry data (e.g. mileage, location) and meter data (e.g. payment information). The meter data might come in batch at a later date, motivating us to find alternative ways to estimate real-time performance without labels.
One idea is to use importance weighting (IW) techniques (Sugiyama et al.). At a high level, we could identify subgroups based on input features, figure out the training SLI (e.g. accuracy) for each subgroup, and weight these accuracies based on the number of points in each subgroup in the live (post-deployment, unlabeled) data. In our example, basic subgroup definitions could be neighborhoods – for each neighborhood in NYC, we’d find the training accuracy and weight it by the fraction of live points in that corresponding neighborhood to get its “estimated” accuracy. Then, we’d aggregate each neighborhood’s estimates to get an overall estimated accuracy. For a more sophisticated (and higher-confidence) approach, we could construct different subgroupings and average the resulting SLI estimates. Again, research challenges lie in identifying these subgroups, and of course – assessing how well such methods work.
We could either identify subgroups in the training set or in the live stream. The cheapest option is to compute subgroups based on training data points, as this can be done once. However, with this “static subgroup” option, real-time SLI estimates become less accurate as subgroup representation changes over time. Thus, we want to compute adaptive subgroupings in the live data. We could leverage streaming clustering algorithms that are explicitly robust to changing data distributions (Zubaroğlu et al.); however, this is extra costly in our case because we would repeatedly need to reassign training dataset points to clusters any time new live data comes in. Additionally, clusters might have few or no corresponding data points in the training set, preventing us from estimating the SLI. Thus, we need to research methods that efficiently identify subgroups in high-dimensional, changing data streams with a reference dataset in mind (i.e. training set).
Partial Feedback
This scenario is the most common amongst ML pipelines I’ve seen “in the wild.” Often, live data is only labeled on a schedule, and more often than not, some upstream data collection issues influence feedback coming in (e.g. there’s a cell tower outage in a region of Tribeca, causing payment meter data to arrive later than expected). Assuming the distribution of label lag is unknown and nonstationary (i.e. it may not be feasible to train a separate model to predict which predictions won’t have feedback), how do we estimate real-time SLIs in this case?
At a first glance, maybe we can simply aggregate the full-feedback and no-feedback estimates, weighted by the count of data points in each subgroup. But the reality is that label lag is rarely uniformly distributed across buckets, and identifying groups of data points that have similar feedback lag times is critical to producing accurate estimates of real-time SLIs6. We could leverage the streaming clustering algorithms as described in the no-feedback section, but such clusters may not be interpretable, or simply described with only a few clauses in the predicate (Saisubramanian et al.). For debugging purposes, we also care about how these clusters of “laggy” data points change over time, or anomalies in lag.
Maybe we can draw inspiration from streaming pattern mining algorithms such as frequent itemsets (Rajaraman and Ullman et al.). However, such algorithms look through groups of features in windows of data points with labels that don’t change, while the data points we want to apply the frequent itemsets algorithm to – the ones that don’t have feedback (i.e. the “laggy” points) – might get feedback after we compute the frequent itemsets. Consequently, how do we extend streaming frequent itemset algorithms to efficiently recompute itemsets after removing data points? We can build on work in incremental maintenance of frequent itemsets (Tobji et al.).
Fine-grained Monitoring: Diagnosing ML Performance Issues
When SLIs are low, the highest priority is to get them back up as soon as possible. The “fine-grained” monitoring category deals with “root cause analysis” for underperforming pipelines – whether models should be retrained or if engineering problems in the pipeline are root causes of failure. Furthermore, if models should be retrained (e.g. there is “drift” or “shift”), how should we change the training set to increase performance?
Detecting Data Quality Issues
Research in data management for ML observability has made strides in automatically identifying engineering issues in data pipelines (Schelter et al., Breck et al.). Techniques such as schema validation, detecting outliers within batches, and constraints on statistics (e.g. expected mean, completeness, and ranges) of features can flag unexpected data quality issues such as broken sensors and incomplete upstream data ingestion. Declaring bounds or expectations might be feasible with a handful of features and high familiarity with the problem domain, but can this scale to high-dimensional settings – for example, when data scientists are throwing 2000 or more features at an xgboost model? Furthermore, drawing the line between “engineering issue” and “drift” is hard, especially if we want to automate detecting issues. Tools like TFX (Modi et al.) allow users to monitor distance metrics of interest like KL divergence and the Kolmogorov-Smirnov test statistic, but these fail in cases where visually-inspected L1 distance is low – which can happen at the scale of thousands of data points (Breck et al.). Strategies to mitigate this problem assume having the number of data points that a FAANG company might be working with (hundreds of millions, if not billions). If outside a FAANG company, what techniques can we use to bridge the gap between empirical drift d(p̂, q̂) and theoretical drift d(p, q) where p and q are two different distributions?
Towards Retraining Models
A massive problem in both research and practitioner communities is that “distribution shift” is a poorly defined and overloaded phrase, causing confusion across the board. When people say “distribution shift,” they refer to a phenomenon where one dataset comes from a different distribution than another dataset. “Distribution shift” could cause an ML performance degradation – for example, models trained on one taxi company provider’s data might perform poorly on data taken from another taxi company provider. This overloaded phrase encompasses different types of shift; for example:
- Concept shift: a change in the relationship between input features and target outputs (i.e. labels). An example of this is end-of-year Wall Street bonuses causing riders to tip more for a week.
- Covariate shift: a change in the distribution of input variables in the training data, not the target output distribution. An example of this is receiving more taxi rides in Midtown (Times Square for the ball drop) on New Year’s Eve.
- Age shift: an expected increase or decrease in the distribution for an input variable over time. An example of this is a taxicab’s total mileage, which can only increase over time.
A lot of research and existing methods in “distribution shift” focus on comparing two finite sets of data. As I’ve mentioned earlier in this series, in practice, we care about deploying models over infinite streams of data, or data for the foreseeable future. Are we supposed to arbitrarily cut production data into two fixed-size datasets to wonder if there is a “distribution shift?” This doesn’t seem right. In the streaming ML setting, the question we really care about is: at what point does my model not work as expected for my current data (i.e. when do I need to retrain my model?).
In reality, decreases in SLIs result from combinations of different types of shift, especially in highly nonstationary environments. Thinking from a product perspective, how actionable is telling a user that “78% comes from concept shift and 22% from covariate shift,” even if we could precisely determine this breakdown? We want to tell users when and how to retrain models post-deployment, given the “abnormalities” occurring in the current window of data. Suppose we have labels or feedback Y and input data or features X, where Xi represents data for the _i_th feature across all data points. In order of increasing granularity, types of abnormalities could include:
- Shift in P(Y | X) but no shift in P(X)
- No shift in P(Y | X) but shift in P(X)
- Shift in P(Xi)
- Shift in P(Xi | Xj) where i ≠ j
- Shift in P(Xi | Xj , Xk , …) where i ≠ j ≠ k
Tracking many distance metrics at scale. As mentioned earlier, to approximate the abnormalities described above, existing works propose tracking metrics like KL divergence and the Kolmogorov-Smirnov tests over both consecutive sliding windows and train sets (i.e. for train-serve skew as described in Breck et al.). Keeping many windows of live data and the train set in-memory might not be feasible, so we could leverage AQP techniques to compute distance metrics with reasonable errors. For example, metric computation functions could run on histograms of features instead of full data streams; however, histogram bins need to change in the streaming setting as data evolves over time. Research challenges lie in combining ideas from incrementally-maintained approximate histograms (Gibbons et al.) with ideas from adaptive histograms (Leow et al.) to produce evolving summaries of windows of data.
Identifying stationarity in distance metrics. Oftentimes, models underperform on weekends, outside of working hours, or on holidays. One interesting idea is to train a model to identify whether there are seasonal patterns in distances between observed P(Y | X) and P(X) in sliding windows. Tracking all combinations of features is impractical (Heise et al.), so is it possible to leverage predicate-finding algorithms (e.g., Wu et al.) to simplify the space of distance metrics to track?
Self-tuning training sets. Finally, based on the types of abnormalities detected, we can suggest ways to augment or change the training set. For example, in the case where P(X) changes but P(Y | X) is the same, we can suggest an upsample of underrepresented subpopulations. In the case where P(Y | X) changes but P(X) remains the same, maybe users can retrain their model on a recent window of data. Research challenges lie in specific, useful hints to construct new training datasets to avoid low performance pitfalls.
Visualizations
Current ML monitoring dashboards are overloaded with information.7 Users see hundreds, or even thousands, of bar charts and graphs trying to visualize “distribution shift.” These charts are not actionable, especially when people can use the same group of charts to tell two conflicting stories. For instance, a user could argue that a model needs to be retrained because a feature’s mean value has plummeted in the last few days. On the other hand, a user could argue that this feature isn’t one of the three most important features, so retraining the model wouldn’t have a large impact. Thus, from an interface perspective, drawing the line on when to retrain a model given hundreds of graphs is an arbitrary process. How do we come up with better visualization tools?
Dashboard goals. The purpose of monitoring visualizations is to help users be in sync with their data and models. To this end, good monitoring dashboard should unambiguously answer specific questions, such as:
- What is the real-time ML performance?
- Is this performance higher or lower than expected? Than required (i.e. meeting SLOs)?
- Is the reason for lower performance a data quality issue?
- Should the model be retrained?
Dashboards should contain only a handful of plots describing the “single metric to rule them all” (i.e. SLIs) so users aren’t overwhelmed.
Dashboard challenges. Visualizing metrics across more than two dimensions is very hard. Unfortunately, we have at least the following dimensions when it comes to ML metrics:
- Metric value
- Components (i.e. joins across components in pipelines, see the single-component vs cross-component discussion in the second essay in this series)
- State (i.e. historical values of inputs and outputs)
- Subpopulation (including groups of features)
- Time (in the generic sense, e.g. plotting the rolling mean of 100-day windows across the last 6 months)
How do we develop visualizations that unambiguously communicate information across all these dimensions without too much cognitive overhead?
Towards insightful visualizations. Coupled with fine-grained monitoring information as described in the earlier section, a good dashboard will have insightful visualizations to give users intuition for how distributions are changing. Existing “state-of-the-art” visualizations that ML engineers use (determined via word-of-mouth, so take with a grain of salt8) include static bar chart histograms comparing two datasets. This is hard to reason about in a streaming ML setting. What new types of visualizations can explain changes in fine-grained metrics? Here’s an example of a “dynamic” violin plot of high tip predictions that shows how the distribution of outputs changes over time:
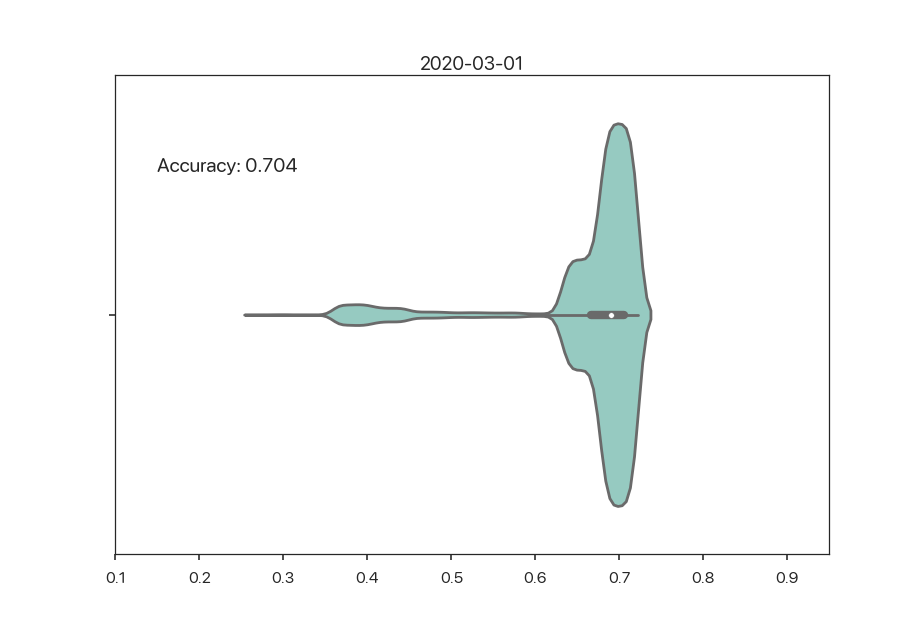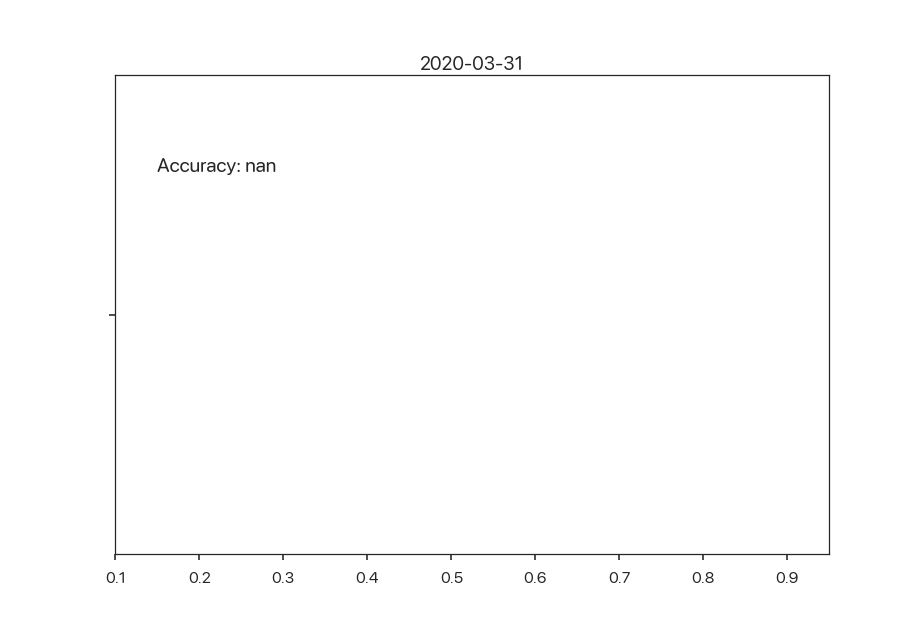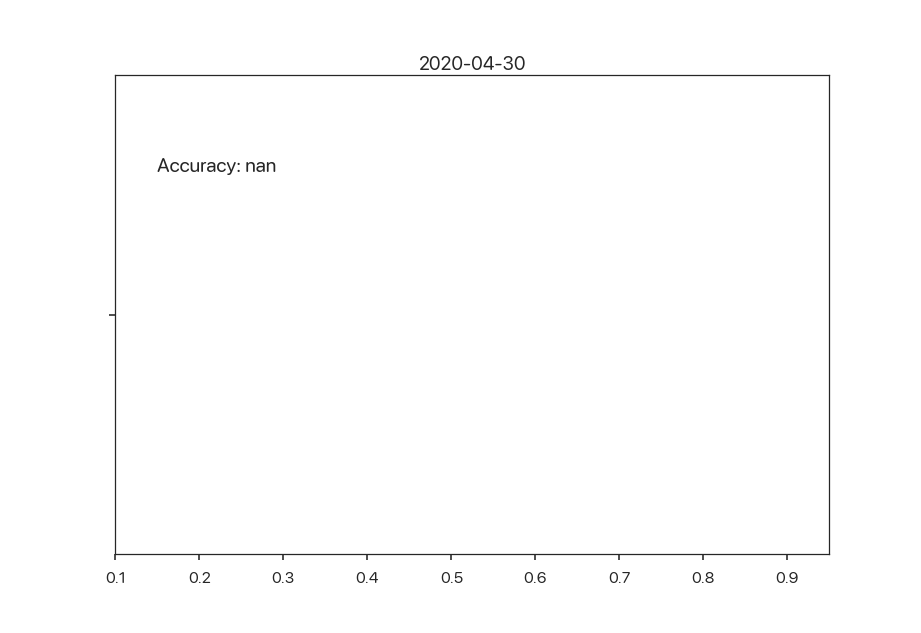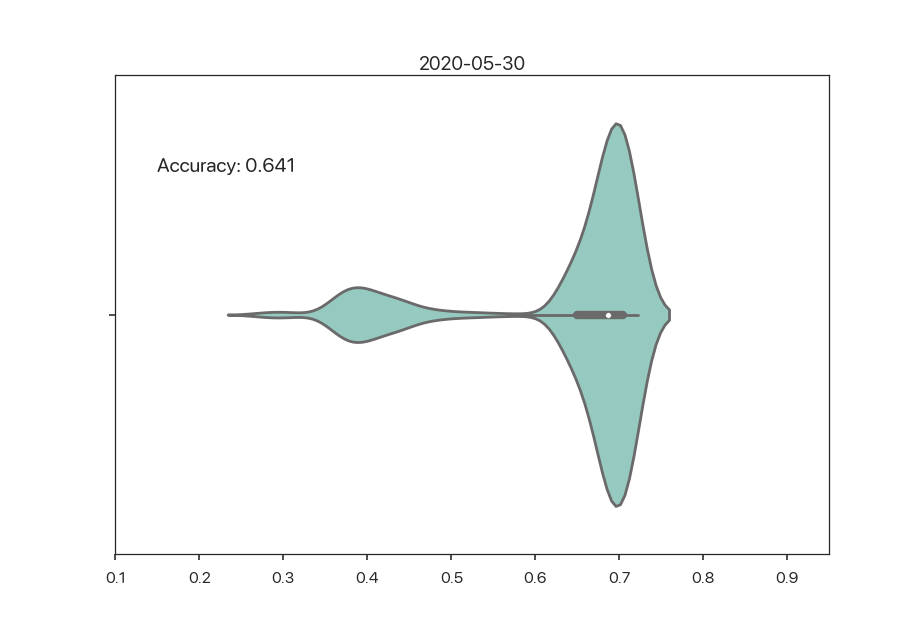 Figure 2: Output distribution over time.
Figure 2: Output distribution over time.
In the example above, there is a confirmed decrease in the SLI (accuracy), as we have full feedback (i.e. all predictions have labels). In cases where we need to approximate the SLI and hypothetically reason about fine-grained metrics, maybe users could intuitively see seasonality in such a visualization. This is definitely not the end-all-be-all solution, but going back to the main point: research challenges lie in principled ways to come up with better visualizations for understanding data drift and automatically presenting these to users based on the data and ML tasks they work with.
Datasets & Benchmarks
Many researchers and developers work mainly with toy data or synthetic distribution shifts due to lack of access to “real-world” streaming ML tasks. To this end, a few problems revolve around datasets and benchmarks to accelerate progress in ML monitoring:
- A repository of real-time streams of data that correspond to tractable ML tasks. Properties of a good data stream include: it’s infinite, representative of a real-world phenomenon, and has an ML task that’s easier to solve than predicting the weather or stock prices. A particularly high-impact problem might be Ethereum gas price prediction. Specifically, can a model output the minimum gas price necessary for a transaction to go through in the next hour with 95% confidence? Another option is to convert existing benchmarks to a streaming format (e.g. samples point xt from train and test distributions (D and D’) from WILDS with a function where xt ∈ D with high probability when timestamp t is small and xt ∈ D’ with high probability when t is large). Ideally, we collect more “temporally evolving tabular data streams,” as this type of data is massively underrepresented in research communities.
- Interfaces for querying data from the repository in an intuitive way. Most data scientists don’t work with streaming systems, so how do we allow them to perform range queries and receive Pandas or PyTorch datasets? How do we safeguard users against label leakage or accidentally peeking into the future when they experiment with new ideas?
- Interfaces (dare I say, a DSL? for creating and evaluating policies for training models, not single model binaries (i.e. as a Kaggle competition would). mltrace’s vision is to be a React-like library where users define components of pipelines with triggers that run before and after every component is run. In these triggers, users can decide to retrain models based on their own criteria – such as data drift metrics or scheduled updates.
Conclusion
With enough context about an ML task, it’s probably possible to solve the data management problems specific to that task. But in building a general-purpose monitoring tool, there are several other challenges that stem from increased ML pipeline and system complexity, including:
- Growing data science teams and tool stacks. Software engineering has shown that fragmentation in teams and tool stacks makes it hard to keep up system sustainability. This will hold for ML, especially when the number of possible ML data management tools largely increases every year. Debugging a model that someone else trained is a pain.
- Model stacking. Many organizations chain models together to produce final predictions. Drift detection is hard enough for one model. Tracing faulty predictions back to the specific model(s) that need to be debugged seems extra challenging.
- Uninterpretable features. Many organizations use ML to produce embeddings that are fed as features to downstream ML tasks.9 Data quality alerts, such as user-defined constraints on feature columns, then cannot be constructed.
- Deploying components as containerized applications. It is hard to do ML in Kubernetes clusters. Containerized infrastructure works well primarily for stateless applications, and unfortunately, online and continual learning is stateful (i.e. model weights are updated and need to be shared across prediction serving pods).
- Multimodal data. Many of the solution ideas I outlined in this piece are specific to tabular data. What techniques can we use in image, audio, and video cases? Dare I say, “data lakes” of information?
I haven’t thought too deeply about these ad-hoc challenges, but I suspect that a good ML monitoring tool will be aware of them at least. Finally, I want to end this series on a personal note.10 I am grateful to have the time to critically think about ML monitoring and the support of both industry professionals and academic collaborators. I am lucky to be in a PhD, and I’m excited for the papers I will be able to write!
Thanks to Divyahans Gupta and my advisor Aditya Parameswaran for brainstorming help and feedback on many drafts.
Notes
Footnotes
-
Usually, I talk about observability. Monitoring is a subproblem within observability, with the most interesting research questions (in my opinion). ↩
-
New challenges arise with model stacking, or chaining models together to create final predictions. ↩
-
Unclear if “coarse-grained” and “fine-grained” are the best terms here. DG suggests “external” vs “internal” metrics. Please let me know if you have any thoughts on this! ↩
-
Based on timely-dataflow (Rust-based differential dataflow implementation). Shoutout to Peter Schafhalter for the quick work on this. ↩
-
I should elaborate on these methods further. ↩
-
Not to mention, determining which subgroups have higher lag times can be helpful for debugging purposes. ↩
-
Not naming any names here, but please check out demos from ML monitoring companies if you are interested. ↩
-
A few of us in RISELab are working on an interview study to formally write about “best practices” for post-deployment ML maintenance. ↩
-
The perils of deep learning fall into this category. ↩
-
Kudos to anyone who has made it through all 4 posts in this series. Seriously. I’m pretty sure I haven’t read all the words in here. ↩