Now that I’ve finished a long year (years, really) searching for a faculty job and accepted an offer, I can finally get back to my usual blogging antics! After coming back from all my interviews, it seemed that AI agents suddenly got a lot better at everything, so I wondered: what are some challenging workflows I did during my PhD, and could AI agents help me automate parts of them?
One workflow that felt particularly interesting to revisit was qualitative analysis.
Qualitative analysis is basically the process of reading a lot of messy unstructured data and trying to figure out what is interesting, recurring, surprising, or important.
Concretely, the question is: What is the “right” way to do agent-assisted qualitative analysis? This is clearly a big research question, and I can’t answer it in one blog post. Instead, I run some cute experiments with naive agentic setups for qualitative analysis, varying how much the human is in the loop, and report what I learned.
First, I’ll give some background on qualitative analysis. Then I’ll describe the experimental setup, go through the findings, and briefly talk about what I think is exciting to work on next.
Throughout, remember that this is a blog post, not a paper :)
Background
Before getting into the experiments, I’ll give some background on qualitative analysis, the specific methodology I used (grounded theory), and why I think this is such an interesting problem for AI systems.
Despite the specialized name, qualitative analysis is a familiar research practice across many fields—not something confined to ethnography or the social sciences. E.g., mining agent logs for failure modes, analyzing narratives in interview transcripts, synthesizing patterns from user-research sessions, and close-reading news coverage for recurring framings all involve qualitative analysis in some form.
Grounded theory
There are many ways to do qualitative analysis. The one I learned during my PhD is grounded theory: a method for answering a research question by building the answer up from the data itself, rather than starting from a fixed hypothesis.
I will illustrate grounded theory with an example. Suppose the research question is why do PhD students seriously consider leaving their program? and the data is interview transcripts with current and former PhD students. Grounded theory usually proceeds in stages:
-
Open coding. We read through the data and attach short labels (codes) to passages of interest. For example, a passage about a stalled project might get coded as “no progress for months”; one about an unresponsive advisor, “absent advisor”; one about feeling behind peers, “social comparison.” As we move through the corpus, we compare new passages against existing codes, merging similar ones and splitting overly broad ones.
-
Axial coding. We group related codes into higher-level categories. For example, “absent advisor,” “shifting goals,” and “no progress for months” might cluster into mentorship breakdown, while “social comparison” and “imposter feelings” might cluster into identity strain. We may also look for relationships between categories.
-
Selective coding. We pick one or two core themes and organizes the rest of the theory around them. Maybe mentorship breakdown becomes the “spine” of the story and the remaining categories are treated as upstream causes or downstream consequences.
Throughout the process, we also writes memos: informal notes about emerging patterns, uncertainties, and possible interpretations.
Why agent-assisted qualitative analysis is a good problem to work on
Qualitative analysis is genuinely hard for humans. It is tedious. It requires manually reading through the data, thinking about it, and deciding what is interesting. Coding a single interview transcript can take hours, plus additional time for finding themes across many interviews. It does not scale easily.
Qualitative analysis is also hard for AI to do because the “right” analysis depends heavily on context outside the corpus itself. In the PhD example above, one researcher might focus on advisor relationships and build a theory around mentorship breakdown, while another might focus on identity, isolation, or academic incentives. Neither analysis is necessarily wrong; they are emphasizing different aspects of the same interviews based on what they think is important and what question they are ultimately trying to answer. This may depend on the researcher’s background, the audience for the work, and more. Doing this well requires a kind of taste and judgment that is difficult to specify explicitly, which makes it a much harder AI-assistance problem than most tasks out there (e.g., with verifiable answers like “did the code compile?”).
Moreover, in qualitative analysis, the evaluation criteria themselves evolve throughout the workflow. Researchers often discover what matters by interacting with the data over many rounds of interpretation. This makes the problem fundamentally difficult for current agentic systems, which tend to assume stable objectives and converge prematurely on fixed framings.
Experiments
With that background, I wanted to see what happens when you point agents at grounded theory and vary how much the human is involved.
Data
I searched for a dataset that was reasonably small (a few hundred data points), where each data point itself is short, that wasn’t already in a benchmark, and that I could have thoughts or opinions on. I ended up scraping 451 tweets posted in reply to a question from Sholto Douglas: “When do you reach for other models instead of Claude? What can we do better?” The replies cover complaints about specific failure modes (Claude getting dates wrong, ignoring instructions, over-editing files, hallucinating APIs), general impressions, comparisons to other models, and the occasional unrelated joke. The question for the analysis is: why are users switching away from Claude?
Agent setups
I ran six different agentic conditions for grounded theory on this data, all using Claude Sonnet through the Agent SDK. They differ on two axes: how much grounded-theory methodology the agent is told to follow, and where (if anywhere) the human is pulled in. I also tried two multi-agent setups: one hierarchical (a supervisor delegates to workers) and one where two independent coders analyze the same data separately and then compare. These are intentionally simple setups—the goal was not to optimize for the best possible system, but to see where straightforward approaches broke down and what kinds of human involvement seemed useful. The table below summarizes the six conditions.
Readers do not need to memorize the setup names; I redefine each one in context when discussing the results.
| ID | Grounded theory described in prompt? | Human involvement | Multi-agent? |
| exp0 | No; the prompt only asks to organize and group complaints. | None | No |
| exp1 | Yes; prompted to follow grounded-theory stages. | None after the initial prompt | No |
| exp2-codes | Yes | After each batch, review the proposed codes in a browser UI: delete, edit, or add codes; optionally highlight phrases in tweets and leave short comments. | No |
| exp2-memo | Yes | After each batch, read the agent's memo and leave written feedback about the analysis direction; optional phrase highlights as in exp2-codes, but no per-tweet code editing. | No |
| exp3-hierarchical | Yes | None | Yes; supervisor develops a coding framework, delegates partitions to worker subagents in parallel, then reconciles. |
| exp3-independent | Yes | After the two coders finish, read a summary of where they disagreed and leave one round of written feedback about the analysis direction. | Yes; two coder subagents code the full corpus in parallel; orchestrator reconciles disagreements. |
Some notes on the mechanics. Each condition uses an LLM agent that can call tools and read/write files. The tweets live in a file on disk; the agent works through them in batches according to its prompt.
In the interactive conditions, after going through a batch, when the agent is ready to solicit human input, it writes a feedback_input.json file with everything the human should see—the current batch of tweets, the agent’s proposed codes, the memo, depending on the condition—and generates the UI code for a review interface (HTML, CSS, and a bit of JavaScript). It then spins up a small Flask server via its Bash tool. The server opens a browser tab with that interface, which is where the human actually does the work: editing codes, highlighting phrases, typing comments. When the human submits, the server writes feedback_output.json, shuts down, and the agent reads the file back and continues.
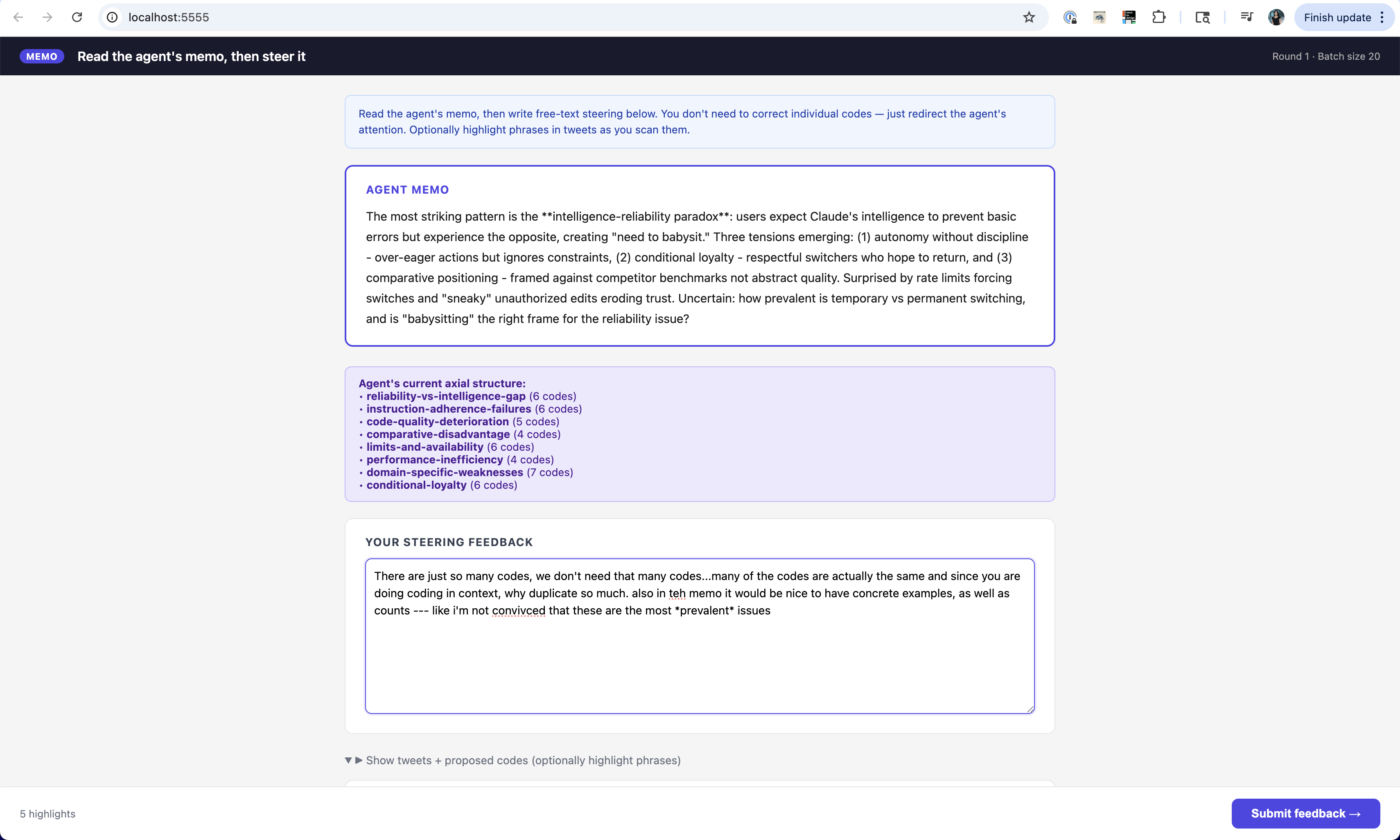
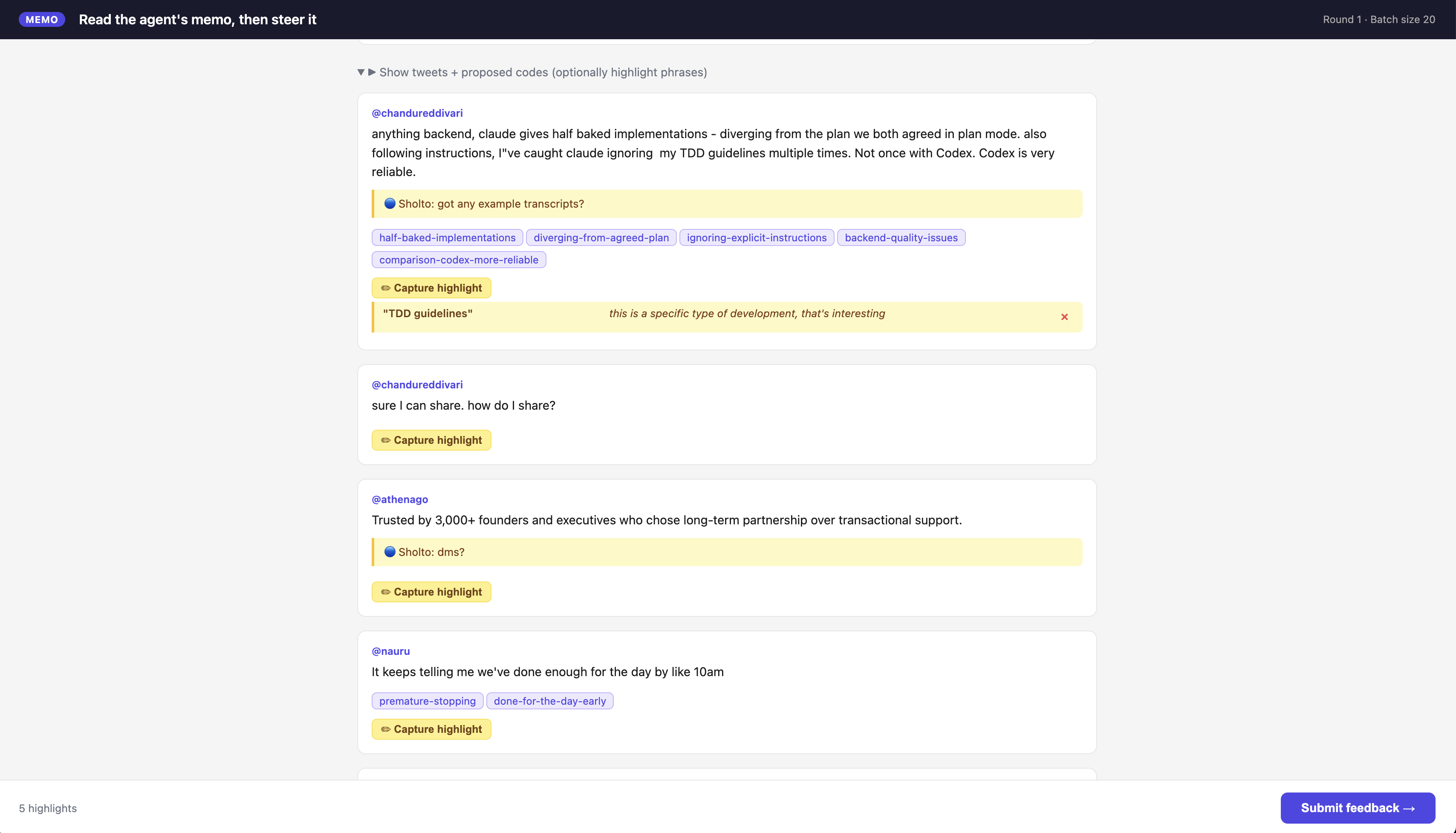
Findings
I spent a few days running these experiments and reviewing the outputs. For the full agent run logs from each condition—prompts, tool calls, thinking blocks, and subagent traces—see the interactive trace viewer (opens in a new tab). Pick an experiment from the dropdown and browse the timeline or event log.
Before diving into the findings below, it’s worth comparing the final report each condition produced on the same tweet corpus (Figure 2)—pick a condition from the dropdown and scroll through the report. The summaries diverge more than you might expect given identical inputs.
Here, I organize the findings into two groups. The first is about what these agents get wrong about the task itself, including how they handle human feedback. The second is about what it feels like to be the human in the loop, including the fatigue, the validation difficulty, and the interfaces.
Agents don’t understand what qualitative analysis is
Agents paraphrase instead of analyzing. One surprising thing I found was that the number of open codes the agent generated per tweet was highly correlated with the length of the tweet (ρ = 0.81 in exp1). For these tweets, though, longer usually meant more elaboration on the same complaint, not more distinct complaints. Upon closer inspection, many of the codes for longer tweets were just restating the same content, as shown in Figure 2 below.
Fortunately, in exp2-memo, where I was able to provide free-text feedback to not simply summarize the tweet, the correlation between tweet length and number of open codes dropped significantly to ρ = 0.15.
Another indication that agents are paraphrasing is that almost every code is used exactly once across the entire corpus. In exp1, 93.8% of codes are for one-time use. In exp2-codes, it’s 100%. This is surprising because the agents are coding in context: when the agent generates codes for a new tweet, all the codes it has already generated for previous tweets are right there in the conversation. It has the full codebook in front of it and could reuse an existing code instead of inventing a new one. But it doesn’t. As shown in Figure 3, the only condition where codes were meaningfully reused was exp3-independent, a multi-agent setup where two independent coders both coded against the same predefined set of categories from the main agent.
Agents don’t code all the data. In each agentic condition, the agent is instructed to go through the entire corpus, and even make multiple passes over it. Unfortunately, agents don’t do this. The agents go through tweets one by one (or, in exp3-hierarchical, spawn subagents to code batches), and at some point they stop and declare the analysis complete. The best condition was exp2-codes, which coded 68% of the 451 tweets. The worst was exp3-hierarchical at 6%. Most conditions covered around 25-35% of the tweets.
Early stopping is only part of the problem. The agents also made mistakes on tweets they did reach. Sometimes they generated the wrong codes for a tweet. Other times, they skipped the tweet entirely by assigning an empty code list. In exp2-codes, for example, the reasoning trace in Figure 5 shows a long tweet from a heavy Claude user being skipped because the agent treated it as “defending Claude, token management advice,” even though the tweet contained concrete complaints about drift, token usage, and needing to manage Claude around rate limits. Another tweet was dismissed as an “unclear mixed message.” Other times, tweets seem to disappear from the processing flow entirely.
exp2-codes reasoning trace and codebook writeReasoning trace: This is another dense batch! Let me code them systematically. I’ll go through each tweet: … [1,317 characters skipped] … Tweet 167: “if model overtrained for safety, move to warmer model like Sonnet 4.5” - safety overtraining driving to older models Tweet 168: Long detailed post about token management - maintaining customizations, pruning skills, not switching models unnecessarily - defending Claude Tweet 169: Offering detailed feedback Tweet 170: “Opus 4.7 awesome for new code”, “debug existing stuff rely on 4.6 because 4.7 gets lost in wild assumptions” - 4.7 making wild assumptions when debugging
Generated codebook update: “167”: [“safety overtraining driving to older models”], “168”: [], # defending Claude, token management advice “169”: [], # offering feedback “170”: [“4.7 making wild assumptions when debugging”, “attribution confusion in long conversations”]
[]).
Agents are bad at managing the work. Human qualitative researchers have basic ways of managing and parallelizing the work: we split the data across researchers so different people analyze different groups, compare notes, sample strategically, and sometimes “pipeline” the task, starting to assemble higher-level categories before every document has been coded. Most agentic conditions did none of this. They processed tweets sequentially, even when parallelism was available. In exp1, one agent said it would parallelize and had a worker subagent configured; however, it made zero subagent calls.
The two explicitly multi-agent conditions did use subagents, but the orchestration was brittle.
In exp3-independent, a top-level orchestrator agent spawned two independent coding agents and asked them to analyze the full corpus separately.
Both subagents timed out after coding only a small number of tweets. After several failed attempts to resume them, the orchestrator agent switched strategies entirely: instead of having the subagents read tweets, it generated Python scripts with different hardcoded keyword heuristics for each “coder.” For example, one coder would assign overly_agreeable whenever a tweet contained “sycoph,” while another assigned codes like backend_implementation_poor whenever a tweet contained “backend” plus words like “half,” “baked,” or “incomplete.” At that point, the “independent coders” were no longer performing qualitative analysis at all; they were effectively doing substring matching with different keyword lists.
The feedback loop between human and agent is poor. There are two ways this goes wrong: agents can overfit to feedback, or they can lose the thread over time.
Overfitting. In exp2-memo, after the agent’s first batch, I wrote in the open-ended feedback field: “I care about explicit competitor comparisons, like tweets saying ‘OpenAI is better for writing.‘” I mentioned it once. In later rounds, the agent kept looking for competitor comparisons, found more of them, and elevated “competitor comparisons” into a top axial category. Essentially, the early pieces of feedback I gave got flagged more often in future tweets, when the better solution would have been to go back and re-code earlier tweets under the updated interpretation.
Losing the thread. The opposite also happened: feedback seemed to matter briefly, then fade. In exp2-memo, I wrote in the open-ended feedback field: “there are just so many codes, we don’t need that many codes.” The agent reacted immediately: it consolidated codes from the first group of tweets and said it would be “more disciplined,” whatever that means. But the change did not stick. Later batches went back to producing mostly one-off codes, and the final codebook still had a 96.5% one-off code rate. In the same feedback, I also asked the agent to make the memo more concrete by adding examples and counts. It did not. Sometimes the agent stopped even more abruptly, responding “OK thanks, done” without any sign that the feedback had changed the analysis.
Summary
Most of the agent failures boiled down to two related problems.
First, the agents converged much too quickly. They rushed toward stable themes and clean interpretations long before I felt comfortable committing to any particular framing. Qualitative analysis is supposed to stay ambiguous and exploratory for a while; the agents instead behaved as if the goal was to collapse uncertainty as quickly as possible.
Second, the agents struggled to adapt to preferences that emerged gradually over time. In subjective workflows, the human often does not know exactly what they care about upfront. My own interpretation evolved as I read more tweets, noticed patterns, and refined what felt important. But the agents either overfit strongly to early feedback or forgot it entirely. They had difficulty maintaining and updating an evolving sense of context across long interaction horizons.
What it feels like to be in the loop
The previous section was about what agents get wrong. This section is about what I experienced as the human reviewer in the interactive conditions: trying to validate the output, getting tired, and dealing with the interfaces.
Validating open codes is tractable but feels wrong. Reviewing the agent’s proposed codes was easy enough; the part that felt wrong was being asked to do naming work instead of judgment work.
- Removing obviously bad codes is easy. Some proposed codes were erroneous or redundant: “half-baked backend implementations” (“backend” was hallucinated), “respect despite leaving” (not useful), and “generating unnecessary code volume” (duplicates “code slop/bloat” already in the codebook). I was happy to click
xon those. - But deciding which plausible codes to cut is hard. When I stared at a list of mostly reasonable codes, they all seemed defensible. However, if I had coded the tweets myself, I probably would have generated far fewer codes because I would have focused only on the ideas that felt most salient. The interaction subtly shifts from what matters most? to can I justify deleting this?
- Adding a missing code was even harder. It was easy to point at a phrase and think, this is important. But turning that into a good code meant inventing a name, choosing the right level of specificity, deciding whether it overlapped with existing codes, and making it general enough to apply elsewhere. That required switching from “review mode” into “authoring mode.”
- Highlighting text and leaving short comments felt much simpler than adding a code. I liked marking the exact phrase that mattered and writing a quick note about why it mattered, if I had anything interesting to say. Many times I simply had nothing interesting to say; I just highlighted part of the tweet—closer to in-vivo coding: copy the words verbatim, even if it a long part of the tweet, and let the agent generate the pithy code.
Validating axial codes is much harder. The taxonomies often looked reasonable at a glance, but they looked reasonable in different ways. Each agentic condition produced roughly 10-12 top-level categories covering familiar territory: reliability, code quality, guardrails, usage limits, and competitor comparisons. But the top-level organization changed across conditions, even when the underlying tweets were the same. This made the taxonomies hard to trust: the issue was not that any one taxonomy was obviously wrong, but that several different taxonomies sounded plausible. Figure 6 shows the largest axial categories from each condition.
To validate open codes, I only have to look at the tweet and ask whether the proposed codes make sense. Validating axial codes consists of more steps: given two codes, do these codes belong together or should they belong in different clusters? And does the axial code name name actually capture the cluster? This requires O(n²) comparisons, over pairs of codes, which is not feasible for humans. Moreover, without example tweets under each category and provenance from category back to evidence, I struggled to truly understand the definition of some of these clusters.
Vague axial codes create a particular trap. A category like “Reliability and Trust” (Figure 6) is so broad that it is hard to argue against: almost any complaint about an LLM could plausibly land there. But this unfalsifiability is not a sign of a good category. It means that when someone proposes a fix for the category, there is no way to evaluate whether the fix is right either. Consider “hallucination” as an axial code. If an automated system tells me hallucination is a top theme in user complaints, I will probably agree. But if it then proposes a code change to “fix the hallucination problem,” I have no basis for trusting that fix, because the category was never precise enough to measure in the first place. Vague codes are easy to believe and impossible to act on.
I was surprised at how bad the UIs were. I was also surprised at how bad the UIs were. There were simple things that would have made the process much easier: marking clusters as “reviewed,” dragging open codes between axial categories, seeing example tweets under each cluster for spot-checking, or visualizing how many codes sat under each category. I also wanted diffs between rounds: e.g., what changed in the memo, which clusters were new, which codes moved.
Even basic ergonomics were broken. The memos and feedback textareas often did not fit in the viewport, so I had to scroll back and forth between reading and responding.
More broadly, agents seem perfectly happy operating over huge amounts of text slop: long reasoning traces, repetitive summaries, verbose intermediate artifacts. Humans are not. After a few rounds of feedback, I found myself avoiding reading the memos because they were cognitively exhausting to read. Perhaps the representations that help agents reason, to get high-quality outputs, are not the same representations that help humans supervise or collaborate with them.
I expected to get frustrated by the wait time, or by sitting around while the agents processed data. However, that was not actually my biggest source of frustration. A chat-style UX where the agent streams reasoning while it works is mostly fine, as long as I am learning something from it.
What felt much worse was doing work that seemed low-leverage or mechanical. If I have to do open coding myself, the interaction starts to feel contrived: I am slower than the model, and I do not want to feel like a labeler or teacher for the AI. Reviewing codes one tweet at a time also became exhausting surprisingly quickly; I often did not want to review more than about 10 tweets. Reviewing the memos was even worse. Many of them felt verbose and sloppy, and after a while I found myself avoiding them entirely. My feedback started dense and detailed, then became sparse over time, partly because of fatigue rather than because the agent was improving.
One thing the agent did do well was summarize what it took away from feedback. After some review rounds, it would explicitly state patterns it noticed in my corrections, like “remove redundant codes” or “stay closer to explicit statements.” That made it much easier to tell whether agents actually considered my feedback.
Looking forward
I’m not convinced agents can “replace” us in qualitative analysis, nor will they ever be able to, because all the context around a qualitative question cannot be distilled into something for an agent. But I came away from these experiments both impressed by what agents can already do and convinced that this is a genuinely exciting area to work on.
Some parting thoughts:
We may not want to preserve existing qualitative-analysis workflows exactly as they are. E.g., open coding, axial coding, memoing, were designed around human constraints. Agents change those constraints. Perhaps there are better ways to structure the workflow: e.g., AI-proposed open codes where the human reranks or weights them, or workflows where open and axial coding happen simultaneously instead of sequentially. Perhaps theoretical saturation should be defined around the human analyst’s learning, rather than whether the agent can still generate distinct new codes.
A separate issue is interface and interaction design. Most of the frustration in these experiments did not come from waiting on the agents. It came from low-leverage supervision, poor visibility into what changed between rounds, and difficulty building trust in the outputs. I want systems that make the agent’s reasoning legible without forcing the human to read pages of text slop; systems that surface provenance, uncertainty, disagreement, stabilization, and evidence directly in the interface.
There is also a scaling question. These experiments used short documents (tweets) at relatively small scale. What happens when the documents are long, like interview transcripts or research papers, where reviewing each one individually would be completely untenable? What about applying this to agent error analysis, where the data itself is agent traces and the goal is to identify recurring failure modes? Or to multimodal and semi-structured data? And doing analysis at the thousand, hundred thousand, or million+ scale?
Overall, the biggest thing I took away from all of this is that agents can do the mechanical parts of qualitative analysis fast, but they have no taste. The interesting design question isn’t “how do we automate qualitative analysis” but “how do we build systems where human taste and agent scale actually compose.” If you’re working on this problem, I would love to read your paper(s)! And if you’re not yet, well, I hope this post gives you a reason to start!